Universities are rapidly introducing rules that limit the use of generative artificial intelligence on university data. The reason is straightforward. Many consumer AI tools allow companies to store or analyze what users type into them in order to improve their systems.
When those inputs include confidential research materials, student records, or other sensitive information, the risks become obvious. For example, a researcher might paste interview transcripts, confidential notes, or student writing into an AI system. Depending on the tool’s terms of service, the company providing the system may be allowed to store or analyze that text.
To reduce these risks, universities increasingly restrict the use of AI tools to versions that the institution has formally licensed. These licenses typically include contracts that specify how companies can store, access, or use data submitted to the tool.
At institutions such as Georgetown University, users can opt into a university-provided version of Google Gemini that runs within the university’s Google Workspace environment. As I explained here, enterprise licenses operate on data within a “data moat” (i.e., enterprise data stays within the company, and doesn’t go to the AI provider).
University administrators may believe that most people lack the time or legal expertise to read and interpret software agreements and determine whether each tool retains the right to use the submitted data for model training. Based on that belief, a common approach seems to be to implement a simple rule: university data should be used only in tools approved and licensed by the institution.
As I discuss below, these rules are not entirely new. Universities have long-established policies governing how institutional data can be stored, shared, and processed by external software services. However, as the lines become unclear on what has AI (or not), I believe the policies that outright ban any non-approved AI tool will soon become intractable and eventually be unmanageable.
When AI Becomes Part of Everyday Software
One challenge is that artificial intelligence is no longer limited to obvious tools such as chatbots.
AI capabilities are increasingly built into the software that researchers already use. As a result, people may be using AI systems without realizing it.
For example, a faculty member might summarize an article in a PDF reader or ask a writing tool to improve a paragraph. These features may rely on large language models even though the interaction happens inside familiar software. For example, in the free Adobe PDF tool one might find:
Writing assistants such as Grammarly now include AI features that can rewrite or expand text.
In many cases, users simply interact with familiar software while the AI component runs behind the scenes. A researcher might summarize a document, rewrite a paragraph, or receive an automatically generated meeting transcript without realizing that an AI system was involved.
Today, AI features appear in many common tools, including:
- document editors
- browser extensions
- meeting transcription tools
- email clients
- note-taking applications
- PDF readers
Several universities have begun performing what I’d say are narrow bans: focusing on software, one at a time.
For example, many universities restrict or block AI meeting assistants because these tools can automatically join meetings, record conversations, and store transcripts on external servers. Services such as Otter.ai, Fireflies.ai, and Read.ai integrate directly with platforms like Zoom, Microsoft Teams, and Google Meet and often connect to users’ calendars in order to join meetings automatically. University administrators have raised concerns that these tools may capture sensitive discussions involving student information, hiring deliberations, or confidential research and then process or store those recordings outside institutional systems.
For example, the University of Massachusetts Amherst blocked Otter.ai and MeetGeek after determining that automatic recording features could violate Massachusetts’ two-party consent law for recorded conversations. Mississippi State University similarly restricted Otter.ai and other third-party meeting transcription services because recordings and transcripts may be stored on external servers beyond university control. Harvard University has also warned against the use of AI meeting assistants that automatically record and summarize meetings, citing risks that sensitive meeting content could be exposed to third parties.
From specific bans to “approved only”
Instead of playing “wack-a-mole” with each new instance of an AI-productivity tool that may become dangerous, some universities often adopt a simpler rule: university data should only be used in software platforms that the institution has formally approved.
Grammarly’s example shows that this approach existed even before the recent rise of generative AI. Many universities, including Georgetown, began offering institution-wide licenses for Grammarly years before large language models became widely embedded in writing tools.
It is difficult to know the exact reasoning behind any individual licensing decision. However, a common pattern in higher education is easy to observe. When a consumer tool becomes widely used by students and faculty, university IT departments often evaluate whether it should be offered through an institution-wide license with stronger data protections.
Take Grammarly. Without an enterprise agreement, Grammarly retains the right to store user text in order to improve its systems. Institutionally licensed versions include contractual restrictions that limit these practices.

However, it can be challenging to outright ban non-approved tools without providing the community any approved alternative. As a result, universities are starting to adapt and either pay for enterprise licenses or develop their own AI tools. For example, the University of Michigan built a custom AI for its community.
Georgetown decided to get an enterprise license for Gemini, as it did for Grammarly. However, choosing to use Georgetown’s Gemini tools comes with important conditions: anyone who choose to opt-in Gemini must also agree to not to connect unapproved AI tools or browser extensions to the Gemini environment and to avoid using personal AI accounts for university business involving non-public data.

The underlying idea is simple. University data should only be processed within software systems approved by the university. For many everyday uses of AI and staff members, this approach could work well, as it is likely to reduce privacy risks while still allowing staff members to access state-of-the-art AI tools.
Research practices, however, sometimes require tools that fall outside institutionally licensed systems.
Where Research Needs Create Friction
Researchers who study artificial intelligence often rely on experimental models, prototype tools, or newly released systems that are not yet available through university licenses. In some cases, the research itself involves developing new AI tools (like I do). It is difficult for universities to establish formal contracts for systems that are still experimental or are being created as part of a research project.
Another issue involves reproducibility. Many institutional AI tools are available only through chat interfaces (like Gemini). In these systems, a user types a prompt and receives a response.
Research projects often require repeating the same procedure many times and doing so in a reproducible way. To do this, researchers should rely on APIs, or Application Programming Interfaces. APIs allow a computer program to automatically send requests to a model rather than manually typing prompts in a chat window. Without this type of access, it becomes much harder to document exactly how an AI system was used in a study or to replicate the analysis later (see our guide to APIs here).
At Georgetown, for example, access to Gemini is currently provided through a user interface but does not include API access. The blanket prohibition of commercial APIs for research purposes is particularly problematic because it not only prevents necessary research uses, but also because most commercial API access (e.g., GPT API) does not retain any data for model training purposes.
Universities face a growing policy challenge.
On one hand, institutions must protect sensitive data and ensure that confidential information is not sent to external software services that lack appropriate safeguards. On the other hand, artificial intelligence is becoming both a widely used research tool and an important subject of academic study. Rules designed to control how software services handle institutional data can, therefore, collide with the practical requirements of research that studies those technologies.
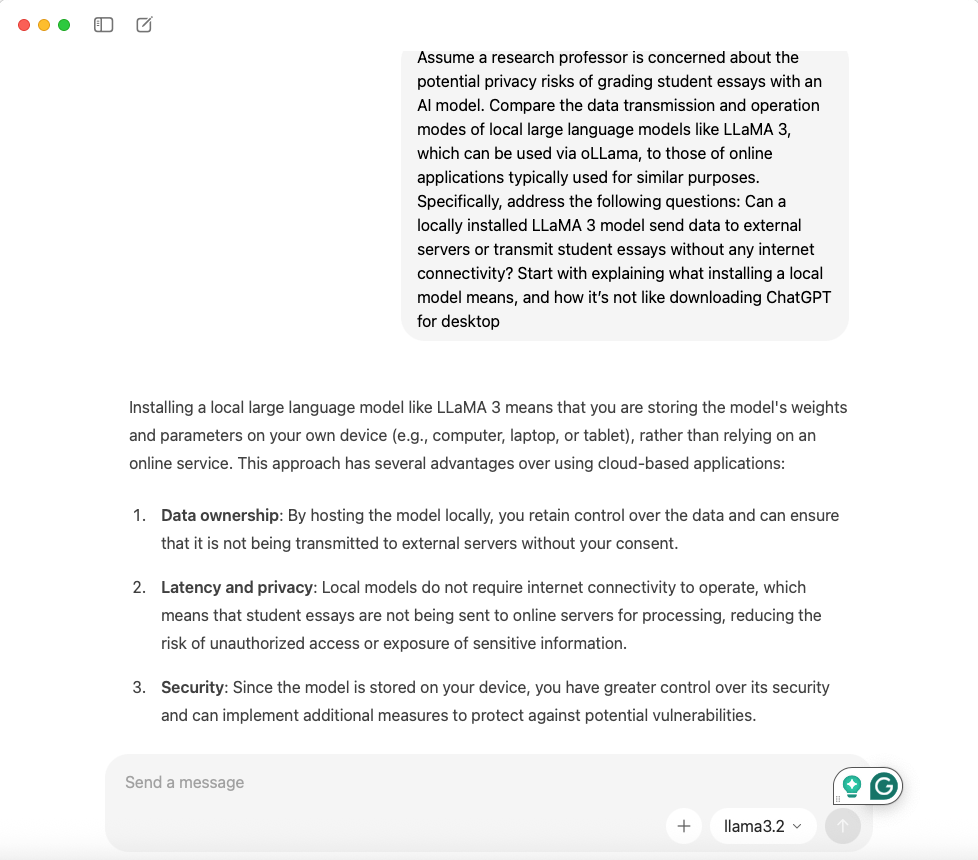
In some cases, the rules may block tools that pose little or no risk to university data. For example, researchers increasingly run open-source large language models locally on secure computers or university servers (like at Michigan).
In these cases, the model runs entirely on the researcher’s own machine rather than sending data to an external company. Because the system operates locally, the data never leaves the computer. If I install Ollama (MAC) or AnythingLLM (Windows) on my personal computer and Llama 3.2, my use of GenAI and LLMs poses no more risky to data privacy than opening a dataset into SPSS or Excel.
These examples illustrate a broader point. University rules about AI tools were largely designed to control how external software services handle institutional data. This makes sense, particularly as many users do not have the willingness or ability to carefully comb through the privacy policy to identify risks.
Research practices, however, often involve experimental tools, locally installed models, or automated computational workflows that do not fit neatly into that model. A more flexible approach will therefore be necessary.
Universities could consider options such as research exceptions, controlled experimentation environments, or review processes similar to those used for data governance or institutional review boards. These mechanisms would allow researchers to use emerging AI tools while appropriately safeguarding sensitive institutional data.
The goal of university policies should not simply be to limit the use of new technologies. It should be to protect institutional data while allowing researchers the freedom needed to study those technologies themselves. As artificial intelligence becomes more deeply integrated into academic work, universities will likely need to refine their policies in order to balance both goals.

Leave a comment